„Ne használj fel mindent, amit az interneten találsz!” – Petőfi Sándor, avagy a plágiumkeresés fortélyai
Használtad már más kódját a saját házi feladatodban? Megpróbáltad már kijátszani az egyetemi plágiumkeresőket? Vajon hogy működhet az egyetemen és a nagyvilágban egy ilyen szoftver? Ilyen és ezekhez hasonló kérdésekre adott nekünk választ Pataki Máté, a SZTAKI KOPI plágiumkereső atyja, amely szoftvert a Szoftver laboratórium 5. tárgynál is használják.
Mit nevezünk plágiumnak?
Számos definíció van, az egyik például az, hogy másnak a művét átveszem, és nem jelölöm meg az eredeti szerzőt. Ez is plagizálás, de vannak finomabb módszerek is. Erre példa, ha a szerzőt megjelölik, de nem lehet tudni, hogy hol kezdődik az egyik szöveg és hol a másik. Én egy közvetett definíciót szoktam inkább használni: Egy olvasó fog egy művet, amelynek ismert a szerzője. Amikor ezt elolvassa, ha meg tudja mondani, hogy melyik a szerzőnek a saját gondolata, és melyek azok a részek, amiket valaki más írt és ő csak parafrázisban átvette, vagy szó szerint idézi, akkor nincs benne plágium. Ha bármelyik nem valósul meg, akkor úgy tűnhet az olvasónak, hogy ez a szerző munkája, akkor az plágium. Ezért nem is lehet teljesen automatizálni a plágiumkeresést, a KOPI sem azt mondja meg, hogy hány százalékban plágium egy szöveg, hanem azt, hogy hány százalékban egyezik egy-egy szöveggel. Az már a felhasználó dolga, hogy megnézze, hogy a szerző megfelelően jelölte-e az idézet eredeti szerzőjét.
Manuálisan hogyan végezhető plágiumkeresés?
Ha valaki olvasott már olyan dolgozatot, vagy cikket, amiben plágium volt, ott gyakran érezhető, hogy a stílus néhány helyen eltér. Főleg a műszaki beállítottságú embereknél szokott előfordulni, hogy egy ideig biceg a helyesírás, aztán hirtelen megjavul, majd megint csökken a minősége. Akkor lehet tudni, hogy az egyik, vagy a másik részre érdemes rákeresni.

Milyen keresők léteznek?
A legnagyobb adatbázissal rendelkező plágiumkereső a Google. Ami publikusan elérhető, azt meg tudja keresni. Ha van egy száz oldalas dokumentumom, akkor viszont nehéz eldöntenem, hogy melyik mondatot írjam be a keresőbe, hogy ellenőrizzem annak a forrását.
Létezik olyan kereső is, ami az írás stílusa alapján azonosítja a szerzőt, de ez az algoritmus még nagyon gyerekcipőben jár. Könnyű átejteni, és sok a hamis találat, de folyamatosan fejlődik. Ha valaki rendszeresen publikál, akkor egy új műről megállapítható, hogy egyezik-e a stílusa a korábbiakkal. Főleg nyelvtani elemzésen esik át a mű, például a szókincs, a tagmondatok hossza és száma.
Van egy olyan rendszer is, ami megnézi az hivatkozásokat, mert ha lemásoltak egy cikket, akkor nagy valószínűséggel vele másolták a hivatkozásokat is. Azt nézi, hogy mennyire sűrűn, milyen hivatkozások vannak a cikkben. Főleg szakmai cikknél igaz, hogy ha valamit kijelentesz, akkor alá kell támasztani, hogy miért igaz, és meg kell jelölni a forrást. Így találtak például orvosi cikkeknél, különböző nyelvek között is nagyon sok plágiumot, mert az idézetek ugyanazok voltak.
Minden online kereső megbízható?
Fontos, hogy vannak ismeretlen eredetű keresők az interneten, például volt egy orosz oldal, amiről később kiderült, hogy visszaéltek a feltöltött anyagokkal. Mindenkinek azt mondta, hogy nincs plágium, de ugyanez az oldal a háttérben árulta ezeket a szövegeket, hogy mások ebből szerezzék meg a diplomájukat. Van még egy most is létező, legálisan működő rendszer, ahova fel lehet tölteni a szöveget és tényleges plágiumkeresést végez rajta. Viszont, ha valaki nem olvassa el figyelmesen a szerződési feltételeket pórul járhat, abban ugyanis benne van, hogy kilenc hónap után publikusan elérhetővé teszi az összes feltöltött dokumentumot. Ezt más művével általában nem is teheti meg senki, de a saját diplomamunkánál is meggondolandó, hiszen ha valaki nem adta be a diplomáját ezen idő alatt, akkor könnyen lehet, hogy valaki más be fogja.
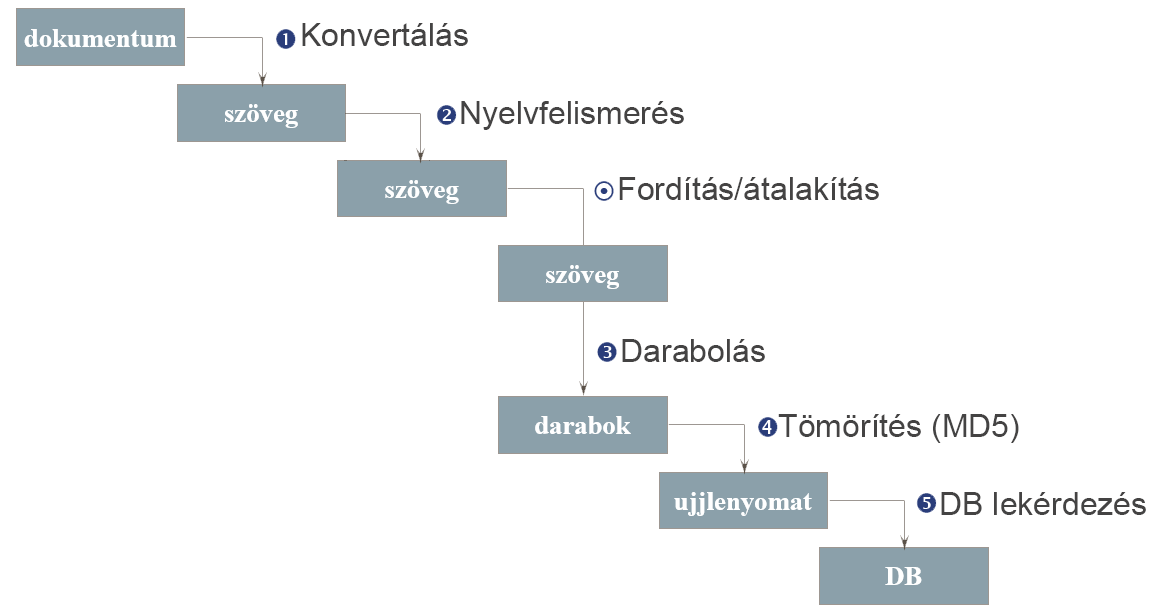
Mi a legelterjedtebb keresési módszer?
A legtöbb kereső feldarabolja a szöveget kisebb részekre, és azt nézi, hogy két dokumentum között mennyi ezeknek a kisebb részeknek az egyezése, hány közös darabot tartalmaznak. Ez többféleképpen is megoldható, vagyis lehet mondatonként vagy tagmondatonként is, de a legtöbb rendszer szavas darabolást alkalmaz. Ilyenkor a mondathatárokat nem veszik figyelembe, csak feldarabolják egy paraméternek megfelelően. Ha például az ötös paramétert használják, akkor minden szónál nyitnak egy öt hosszú ablakot, ahol minden egymás melletti öt szó sorra fog kerülni. Ha megvannak a darabok, akkor a legtöbb rendszer valamilyen hash funkcióval tömöríti (pl.: MD5), hogy könnyebben lehessen tárolni, és adatbázist készít belőle. Az MD5 kódolás során az adatból egy hexadecimális hash készül, amely nem visszafejthető. Azok az elenyésző esetek, amikor ezek ütköznek, nem jelentenek problémát, mert kicsi a valószínűsége, hogy több egymás utáni darabnak is, amik nem egyeznek szabadszövegesen, az MD5-je egyezni fog. Az adatbázis feltöltése után le lehet kérdezni, hogy milyen dokumentumokban vannak benne az aktuális dokumentum darabjai és melyikben mennyi.
Mi alapján választottátok ki az optimális paramétert a daraboláshoz?
Erre futtattunk kísérleteket. Minél nagyobb, annál kevésbé találja meg a kisebb egyezéseket. Minél kisebb, annál jobban megtalálja, ugyanakkor nagyobb lesz az adatbázis és lassabb a keresés. Ha viszont túl kicsire választják, akkor stílust fog nézni. A legkisebb, amit a magyar nyelvben alkalmazni tudnak, az a hármas darabolás. Három egymás melletti szó általában elég egyedi ahhoz, hogy ne a véletlen műve legyen az egyezés. A kétszavas darabolás már inkább az írás stílusára jellemző, a kifejezések, szókapcsolatok miatt is alkalmatlan plágiumkeresésre, az egyszavas meg tulajdonképpen csak azt tudja megállapítani, hogy azonos nyelven íródott a két mű. Az optimális a nemzetközi kutatások szerint is háromtól ötig terjed. Öt fölött már romlik a keresés hatékonysága, kisebb egyezéseket már nem talál meg, és könnyebb tudatosan megkerülni is. A KOPI-ban három szavas darabolást használunk, amelyre pár éve álltunk át. Korábban tíz szavas darabolást használtunk, ennek egyszerűen anyagi, illetve teljesítmény okai voltak, ezt bírta el az akkor használt szerverünk.
Volt olyan keresési módszer, ami nem terjedt el?
Volt egy külföldi rendszer, ami kitörölt pár szót a szövegből. Ezek után megkérték a gyanús szerzőt, hogy egészítse ki a szöveget, írja be a kitörölt szavak helyére azt, ami szerinte oda való. Az igazi szerző nagy valószínűséggel ugyanazokat a szavakat használta, hiszen az az ő szókincse, míg mások gyakran más szavakat, szinonimákat illesztenének be. Evvel az volt a baj, hogy nem tudta meghatározni az eredeti szerzőt, illetve művet, akkor se, ha kiderült, hogy valószínűleg nem ő írta, valamint szükség volt arra, hogy meggyanúsítsák az illetőt.

| Robinson Crusoe | Harry Potter és a bölcsek köve | Harry Potter és a Tűz Serlege | Galaxis útikalauz stopposoknak | A Gyűrűk Ura: A Gyűrű Szövetsége | |
|---|---|---|---|---|---|
| Karakterek száma | 480538 | 335007 | 848630 | 208392 | 771146 |
| Szavak száma | 121839 | 80624 | 197473 | 47978 | 190732 |
| Különböző szavak száma | 6038 | 5764 | 10227 | 5962 | 8700 |
| Átlagos szóhossz | 3.94 | 4.16 | 4.30 | 4.34 | 4.04 |
| Mondatok száma | 2859 | 6711 | 15798 | 3741 | 13560 |
| Átlagos mondathossz (szavak) | 42.62 | 12.01 | 12.50 | 12.82 | 14.06 |
| Tagmondatok száma | 16787 | 12476 | 31290 | 6438 | 26440 |
| Átlagos tagmondathossz | 7.26 | 6.46 | 6.31 | 7.45 | 7.21 |
| Átlagos mondatonkénti tagmondatok száma | 5.87 | 1.86 | 1.98 | 1.72 | 1.95 |
A fordítási plágiumkeresés volt a doktori témád. Hogyan működik az algoritmus?
Nem párszavas darabolást használ, mert a fordítás során a szórend nagyon változó lehet. Mondatonkénti darabolást alkalmaz, és a mondatokat lefordítja az összes lehetséges szóval, ami szóba jöhet a fordításnál. Utána egy hasonlóságkereső adatbázisban keres olyan mondatokat, amikben minél több megvan ezekből a szavakból. Ha megvannak a mondatok, akkor összehasonlítja őket, hogy tényleg párban legyenek ezek a szavak. Tulajdonképpen pontozza a találatokat. Minél több szónak van meg a fordítása a másik mondatban, annál jobb a találat, ugyanakkor a hiányzó fordításokat meg negatív előjellel veszi figyelembe. Ehhez a SZTAKI Szótárat és egy szinonima szótárat használ.
Miért pont ezt a témát választottad?
Amikor önálló labor témákat választhattunk, volt egy olyan téma, aminek a keretében egy ausztrál egyetemmel lehetett együtt dolgozni, és ez a plágiumkeresés volt. Nem állt tőlem messze a téma, de az indok inkább az volt, hogy így kommunikálhattam angolul, vagyis gyakorolhattam a nyelvet. A munka nagyon érdekesnek bizonyult, így ebből írtam a diploma dolgozatomat. Amikor az egyetem után a SZTAKI-hoz kerültem, ott jelentkeztünk egy pályázatra, hogy írnánk az országnak egy plágiumkeresőt. Ezt megnyertük, és innentől fogva újra ezen dolgoztam. A fejlesztés 2003-ban indult el, és 2004-ben lett belőle publikus szolgáltatás, a SZTAKI KOPI Portál. A név szándékosan hasonlít az angol copy szóra, de egy rekurzív betűszó, kifejtve: KOPI Online Plágiumkereső és Információs Portál
Mennyi ideig tartott a fejlesztés?
Az első változat elkészítéséhez körülbelül egy évre volt szükség, de azóta szinte folyamatosan dolgozunk rajta. Egy nagyobb ráncfelvarrás volt 2007-ben. Fordítási plágiumot pedig 2011-ben tudott a világon elsőként keresni.
Milyen nehézségekbe ütköztél a fejlesztés során?
Az egész keresés óriási adatbázisokon történik, így rengeteg erőforrásra van szükség. Minden leselejtezett, vagy új gépen, amire rá tudtam tenni a kezemet, plágiumkeresés futott. Régen egy szerveren futott az egész rendszer, de most már nagyrészt felhőalapú, így ha bármelyik szerver kiesik, akkor az nem jelent problémát.
Melyik nyelveket ismeri fel a KOPI?
Jelenleg az angol, a magyar, a német és a francia nyelveket támogatja a fordítási plágiumkereső. Lehet még bővíteni, csak szótár kell hozzá és az, hogy fel tudjuk bontani az adott nyelvet szavakra és nyelvtanilag elemezni, szótövezni, de ez a legtöbb európai nyelvre működik. Az egynyelvű keresés is ezekre a nyelvekre adja a legjobb találatot, de a legtöbb latin ábécés nyelvre jól működik és használható.
Milyen különbség van a beszélt és a programozási nyelvek közötti összehasonlítás között?
A programnyelvekre egyáltalán nem működik a KOPI, mert ott az írásjelek is számítanak, míg a KOPI által használt algoritmus kiszűri az összes írásjelet, amik viszont fontosak a programozás során. Kódolás közben nagyon könnyű szisztematikusan kicserélni a változóneveket szinonimákra, vagyis átnevezni őket, és kicserélni a ciklusokat. Erre van a Műegyetemen egy szoftver, ami gráfot rajzol a szoftver futásáról, és ezeket a gráfokat hasonlítja össze.
Létezik más fordításiplágium-kereső algoritmus is?
Igen, van az egynyelvű keresésnél is használt szavas darabolásnak egy adaptált változata. A lényege röviden, hogy a szöveget egy automata fordítóval lefordítják a másik nyelvre, és arra futtatják a sima egynyelvű keresést. Ennek az előnye, hogy ugyanazt az adatbázist használhatják, mint az egynyelvű keresésénél, amiben gyorsan, indexáltan tudnak keresni. Hátrányát valószínűleg senkinek se kell részletesen magyaráznom, aki használt már gépi fordítót. Az eredmény elég megbízhatatlan, és nagyon függ a minősége az adott nyelvpártól és a szöveg összetettségétől, szakterületétől.
Magyarra sokkal rosszabban működnek ezek az algoritmusok, mert ennek a nyelvnek nem kötött a szórendje. Magyarban egy mondat sokféleképpen elmondható. Ha megcserélem a szavakat, akkor nem értelmetlen mondatot kapok, hiszen a ragok továbbra is megmaradnak. Ilyen példamondat a következő: „A vadász lelőtte a medvét.”, mely megcserélve „A medvét lelőtte a vadász.”. Ez nálunk ugyanaz, de az angolban két szót felcserélve már a medve lőtte le a vadászt, így ott nagyobb valószínűséggel adja ugyanazt a szórendet a gépi fordító, mint az ember.
Segíti a másolásvédelem a plagizálás megelőzését?
A másolásvédelem előnye, hogy megnehezíti és körülményessé teszi a másolást. Bizonyos esetekben a mű útja és a felhasználása nyomon követhető, például DRM használatával. A DRM-technológia célja, hogy ellenőrizze a hozzáférést, nyomon kövesse és korlátozza a digitális művek felhasználását. De nagy hátrányai is vannak. Nehezíti a legális felhasználást is, mert kényszerítheti a felhasználót arra, hogy letöltsön egy olyan olvasóprogramot, amit ők szeretnének. Vagy ha például látássérült az illető és felolvasóprogramot használ, akkor nem fogja tudni ezeknek egy részét használni, mert gyakran úgy vannak kódolva, hogy ne lehessen felolvasni ilyen programokkal.
A tudományos életben fontos, hogy amit én írok, azt mások elolvashassák és hivatkozhassanak rá. Ha viszont ráteszek egy másolásvédelmet a cikkemre, és még a Google sem tudja elolvasni, akkor onnantól fogva senki se fog hivatkozni a művemre, vagy legalábbis sokkal kevesebben. Ráadásul hiába másolásvédett egy dokumentum, mert amint megjelenik a képernyőn, már lefotózható, OCR-ezhető. Az OCR lehetővé teszi a szkennelt dokumentumok szöveggé történő átalakítását. De alapvetően lehet másolásvédelmet és plágiumkeresőt együtt használni, mindkettő meg tudja védeni a dokumentumot. Szerintem a legjobb másolásvédelem az a vízjelezés, olyan módon, hogy látható, hogy egy letöltött fájl például kinek a tulajdona. Ilyet használ többek között a Typotex kiadó is . Háromszor is meggondolom, hogy odaadom-e a saját magam által letöltött fájlt valakinek, amin rajta van a nevem, mert ha kiszivárog, akkor nekem kell magyarázkodnom miatta.
A plágiumkeresők milyen dokumentumokkal dolgoznak?
Csak a feltöltött, illetve az interneten szabadon elérhető dokumentumokkal tudnak dolgozni, hiszen ezek vannak az adatbázisukban. Látszólag ez egy gyenge pontjuk. Ugyanakkor az egyetemeken adott témákban írnak szakdolgozatot, és jellemzően sokan rátalálnak ugyanazokra a forrásokra, anyagokra. Ha nem is lesz meg az eredeti forrás (például tankönyv) a plágiumkereső adatbázisában, legalább lehet látni, hogy az egy átvett rész, és van valahol egy eredeti mű.
Mi a helyzet a szkennelt dokumentumokkal?
A KOPI-ba már beépítettük az OCR-t is, így ha nem tudja értelmezni a dokumentumot, akkor feltételezi, hogy fényképként van benne. Nagyon sokan, főleg az idősebb generációban és az államigazgatásban szkennelt dokumentummal dolgoznak, így merült fel az igény. Ez akkor is igaz, ha nem fénykép van benne, hanem egyszerűen el van kódolva. A pdf-et átalakítja oldalanként külön képpé, arra a képre futtat egy OCR-t, és utána összefűzi ezeket a szövegeket.

Mekkora a KOPI adatbázisa?
Már pár hónapja nem dolgozom a SZTAKI-nál, így pontos, friss adatot nem tudok, de több, mint 30 000 felhasználó, és több mint 60 000 dokumentum van már benne valószínűleg, és ez csak a közvetlen adatbázis, amit a felhasználók töltöttek fel. Van egy hatalmas, folyamatosan bővülő internetes adatbázis is, ami internetről letöltött dokumentumokat tartalmaz. Ezenkívül a teljes magyar és angol Wikipédiában is keres, és ott tud fordítási plágiumot is keresni, ami annyit jelent, hogy például ha valaki lefordít magyarra egy szöveget az angol Wikipédiából, akkor a KOPI meg tudja mondani, hogy azt a magyar szöveget honnan fordították.
Hány felhasználója van a KOPI-nak?
Az elején elég kevesen használták, mert a legtöbben még nem is tudtak a plágium problémájáról. Amikor ez a probléma középpontba került, akkor megugrott a használat. Sokan nem gondolnak bele, hogy amikor plagizálnak, akkor nyernek vele 1-2 hétnyi munkaidőt, de amikor a karrierje csúcsán van az valaki és másoknak érdeke, hogy őt lebuktassák, akkor nagyon sokat veszíthet vele. Vagyis a nyereségük csak látszólagos, viszont nagyon nagy kockázatot vállalnak.
Átverhető a gépezet?
Röviden: át. Hosszabban: nagyon nehezen. Ha valaki egy diplomadolgozatot le szeretne másolni, akkor minden harmadik szót meg kell változtatnia úgy, hogy szinonimát sem használhat, mert a KOPI is használ szinonima szótárat. Egy hosszabb szöveget ennyire megváltoztatni nagyon sok munka, és az eredmény könnyen egy olyan bonyolult szöveg lehet, amit ugyan a plágiumkereső nem talál hasonlónak, de az olvasó se érti meg. Aki egy teljes diplomát át tud írni úgy, hogy a KOPI ne találja meg, az valószínűleg kétszer-háromszor annyi időt eltöltött ezzel, mintha becsülettel megírta volna a szakdolgozatát. Aki ilyen szorgalmas, az már megérdemli a diplomáját, bár lehet, hogy inkább műfordítóit és nem mérnökit, de valamit mindenképp. Az egyébként, hogy valaki feltölti a KOPI-ba a dokumentumát és éppen nincs találat, nem jelenti azt, hogy nincs plágium, hiszen lehet, hogy egy év múlva megtalálja, mert addigra változni fog az adatbázis, vagy javul az algoritmus.
Mi a jövő?
Ez a szakterület hatalmas lépésekben fejlődik. Elég csak arra gondolni, hogy míg pár éve még elképzelhetetlen lett volna, hogy egy fordításra ráismerjünk, addig ma már a gyakorlatban is használható, jól teljesítő algoritmusaink vannak erre. Valószínű, hogy a – korábban említett – szerző azonosítására is pár éven belül lesznek jól használható algoritmusok, melyek megkönnyítik például a bérdolgozatok kiszűrését, mert nem csak azt tudják megállapítani, hogy nem az illető műve a diploma, hanem rá is tudnak keresni az adatbázisban, hogy mely más dolgozatokat írta ugyanaz a szerző. Ugyan nem algoritmikusan, de egy kézi keresés során buktattak le már így olyanokat, akik mással íratták meg a diplomájukat.
A másik fontos fejlesztés, ami már ma is látszik, az a dokumentumon belüli plágiumkeresés. Ez nagyon hasonlóan működik, mint amikor egy személy elolvas egy dolgozatot és csak a stílusok változásából megállapítja, hogy mely részek azok, amelyeknek valószínűleg nem ugyanaz a szerzője. Ha ez az algoritmus valamennyire megbízhatóan működni fog, akkor már a gyanús részekre is rá lehet keresni a nagy webes keresőkben, valamint az oktatók is jobban oda tudnak figyelni azokra a részekre.
A KOPI plágiumkeresőt megtalálhatjátok a https://kopi.sztaki.hu/ weboldalon.
Ez az interjú eredetileg az Impulzus XLII. évfolyam 4. számában jelent meg, melyet letölthetsz az archívumból.
Köszönet a képekért Pataki Máténak!